Installation
Deployment preparation
Downloading
Download and unpack the BAF distribution kit onto the machine where you plan to install it. To do this, use the command below:
$ curl --output baf.zip distribution link
In the curl request, specify a link to the BAF distribution kit (zip file). A link to the folder that contains the distribution kit and pdf documentation will be sent to you in the email.
Next, move the license file face_sdk.lic (the file is attached to the email) to the setup folder.
Contents of the distribution kit:
- ./cli.sh: entry point to run the commands
- ./cfg: folder with configuration files
Further commands are to be executed in the system console from setup directory.
Software installation
To install Docker, Kubernetes and Helm on Ubuntu, use a script supplied with the distribution kit (the Internet connection is required).
$ ./cli.sh smc package install
Uploading of images
First, upload the product images from the archive to the local registry:
$ ./cli.sh generic load-images
Then, upload the infrastructure images from the archive to the local registry:
$ ./cli.sh smc load-images
Configuration
Basic configuration
Enter environment variables
Open the configuration files below in a text editor, set values for the variables and save changes.
| Configuration File | Variables |
| ./cfg/smc.settings.cfg |
|
| ./cfg/license-server.settings.cfg |
|
| ./cfg/platform.secrets.json |
|
| ./cfg/platform.values.yaml |
|
| ./cfg/matcher.values.yaml |
|
| ./cfg/baf.secrets.json |
|
| ./cfg/baf.values.yaml |
|
| ./cfg/platform-ui.values.yaml |
|
| ./cfg/lrs.secrets.json |
|
| ./cfg/lrs.values.yaml |
|
| ./cfg/stunner.secrets.json |
|
Docker settings for GPU usage (optionally)
Docker configuration
To set nvidia-container-runtime as the default low-level runtime, add the following lines to the configuration file located at /etc/docker/daemon.json:
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
Applying configuration
To apply configuration, restart docker-service using the command below:
$ sudo systemctl restart docker
Check that the docker service is running successfully:
$ sudo systemctl status docker
Extended configuration
GPU settings
To enable GPU in BAF you need to edit the file ./cfg/image-api.values.yaml. To do this, set 1 in the variable processing.services.face-detector-template-extractor.configs.recognizer.params.use_cuda:
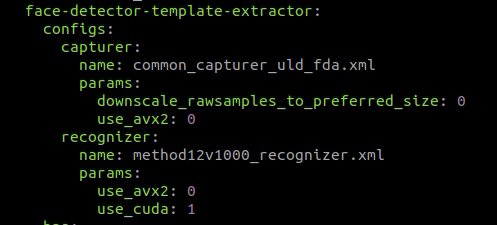
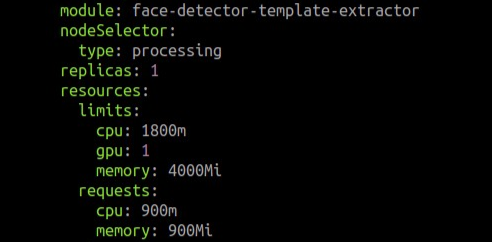
Set 1 for processing.services.face-detector-template-extractor.resources.limits.gpu:
Install and configure a cluster
If you already have a deployed cluster, move to Configure licensing section.
To create and configure the cluster, run the following commands:
$ ./cli.sh smc install
$ ./cli.sh platform db-create-mountpoint
$ ./cli.sh platform install-secrets
This commands:
- Create database mount point.
- Initialize a cluster.
- Install the secrets.
To use GPU in a cluster, install NVIDIA device plugin:
$ ./cli.sh smc nvidia install
Cluster health check
After initializing the master node, make sure that all nodes are ready for operation and have the Ready status. You can check this by running the command below:
$ kubectl get nodes
As a result, the following output will be displayed in the terminal:
NAME STATUS ROLES AGE VERSION
master-node Ready control-plane,master 11d v1.23.8
To check all cluster components, run the following command:
$ kubectl get all --all-namespaces
Configure licensing
The user has 3 license activation options: trial period activation, online and offline license activation.
Install and run a license server
Before installation, open the license-server.settings.cfg file and set the IP address of the machine, on which the license server will be installed, in the license_server_address field.
Run the command below to install the license server. If license_server_address differs from the host address of the machine where the deployment is taking place, it will be set via sshpass.
$ ./cli.sh license-server install
Check that the license server is in the Running status:
$ ./cli.sh license-server status
Console output example:
floatingserver.service - Floating License Server
Loaded: loaded (/etc/systemd/system/floatingserver.service; enabled; vendor preset: enabled)
Active: active (running) since Tue 2022-12-20 12:25:54 +05; 1min 48s ago
To check that the license server is available, follow http://<license_server_address>:8090 in your web browser. As a result, you should be redirected to the login form.
Trial period activation
Please note that:
- The Internet connection is required.
- Running on a virtual machine is not allowed.
The trial period is activated the first time you launch BAF.
Online license activation
Before activation, make sure that the key field (from file ./cfg/license-server.settings.cfg) contains the license key.
Run the license activation command:
$ ./cli.sh license-server activate
When license is successfully activated, the console will return the following result:
[2022-12-20 12:25:53+05:00] INF Activating license key...
[2022-12-20 12:25:54+05:00] INF License activated successfully!
Offline license activation
Before activation, make sure that the license_key field (from file ./cfg/license-server.settings.cfg) contains the license key.
For offline activation, set "1" in the enable_offline_activation field in the license-server.settings.cfg file.
Run the command below to generate an offline license request:
$ ./cli.sh license-server generate-offline
As a result, the request-offline.dat file should appear in the setup directory.
Send the generated request-offline.dat request file to baf-request@3divi.com. The license file will be submitted in the response email.
Copy the received license file to the setup folder.
Open the configuration file license-server.settings.cfg in a text editor and fill in the variable license_offline_activation_file with the license file name and its extension, if present, separated by a dot.
Run the license activation command:
$ ./cli.sh license-server activate
When license is successfully activated, the console will return the following result:
[2022-09-08 01:30:36+05:00] INF Offline activating license key...
[2022-09-08 01:30:36+05:00] INF License activated successfully!
Deployment
Launch deployment
Install facial recognition subsystem (OMNI Platform)
Run the installation of the first OMNI Platform module:
$ ./cli.sh image-api install
Install matcher (matcher-router + matcher-shard):
./cli.sh matcher install
Run the installation of the second OMNI Platform module:
$ ./cli.sh platform install
If necessary, run the installation of OMNI Platform web interface:
./cli.sh platform-ui install
To continue the installation, open the /etc/hosts file and add the following lines at the end of the file:
<external_ip_address> : <platform_domain>
<external_ip_address> : <baf_domain>
Install the subsystem for estimation of Liveness Reflection (LRS) (optional)
If you don't need to record a video of the attempts and also Liveness Reflection checks, skip this step.
In the Registration by Selfie scenario LRS provides the ability to save video attempts (beta) and detect a video stream injection attack.
Create a directory to store the object store data using the command:
$ ./cli.sh lrs minio-create-mountpoint
Run the command to generate LRS tokens:
$ ./cli.sh lrs generate-token
Example of output to the console:
sha256:2473ba0ebf5ef66cd68b252bba7b46ae9f7cc3657b5acd3979beb7fbc5d8807f
Fernet key: ......
Access token: ......
As a result, you will get two tokens that need to be written in the configuration file ./cfg/lrs.secrets.json in the section lrs-tokens.
Run the command to install the LRS secrets:
$ ./cli.sh lrs install-secrets
Run the command to install the LRS:
$ ./cli.sh lrs install
Install the stunner subsystem for proxying requests through TURN server to LRS (optional)
The stunner subsystem is required to successfully establish a connection between client browsers and the LRS subsystem server to record video. Skip this step if you have not installed the LRS module.
Run the command to install stunner secrets:
$ ./cli.sh stunner install-secrets
Run the command to install the stunner:
$ ./cli.sh stunner install
Use the following commands to verify that the stunner is running:
$ kubectl get pods | grep stunner
$ kubectl get svc | grep -P 'tcp|udp|stunner'
If all pods have a Running status and 5 services are running, then stunner is running successfully.
Run the command to obtain the ports on which the TURN server is accessible from the outside:
$ ./cli.sh stunner get-ports
Example output of the command:
tcp-gateway: 31021
udp-gateway: 30796
Install BAF
Get a token from OMNI Platform:
$ ./cli.sh platform get-token - http://<platform_domain> <platform_user_email>
As a result, you will receive a token that must be written to the configuration file ./cfg/baf.secrets.json in the platform-token section.
Next, initialize the BAF secrets for the cluster:
$ ./cli.sh baf install-secrets
Run BAF installation:
$ ./cli.sh baf install
To monitor the deployment process, open another terminal tab and enter the following command:
$ watch 'kubectl get pods'
Configure DNS server
To provide access to BAF, DNS server on your network should contain a record that domain is available at <external_ip_address>.
For testing you need to fill in IP address and domain in the /etc/hosts file on Linux or C:\Windows\System32\drivers\etc\hosts on Windows.
To do this, add a new line like <external_ip_address> <host> at the end of this file, set the values for the corresponding variables and save the file. Note that you need to have administrator privileges to edit the hosts file.
Scalability
When the load increases, the following services can be scaled in manual mode to stabilize BAF operation:
- image-api-liveness-estimator is the service used to detect a face and determine if the face in the image is real or fake.
- image-api-age-estimator is the service used to estimate a person’s age from a face image.
- image-api-gender-estimator is the service used to estimate a person’s gender from a face image.
- image-api-mask-estimator is the service that detects if a person in the image is wearing a medical mask.
- image-api-emotion-estimator is the service that estimates a person's emotions from a face image.
- lrs-lrs: video processing and saving service.
To scale the service, run the command below:
$ kubectl scale deployment <SERVICE_NAME> --replicas <COUNT>
where SERVICE_NAME is a service name (for example, gateway-dep), and COUNT is a number of service instances.
To keep the load of A requests/sec for image processing, on a server with a physical number of CPU cores equal to B, you should set the value of replicas of each of the specified services according to the formula min(A, B).
To save the scaling settings open the ./cfg/platform.values.yaml and ./cfg/image-api.values.yaml files, find the replicas field in the service module, and set new values.
During next installations services will be automatically scaled to the specified values.