Use cases
The diagrams in this section show possible use cases and connection between Face SDK objects and processing blocks. Input data is indicated in blue, data processors are indicated in green, and output data is indicated in purple.
Face estimation in video stream
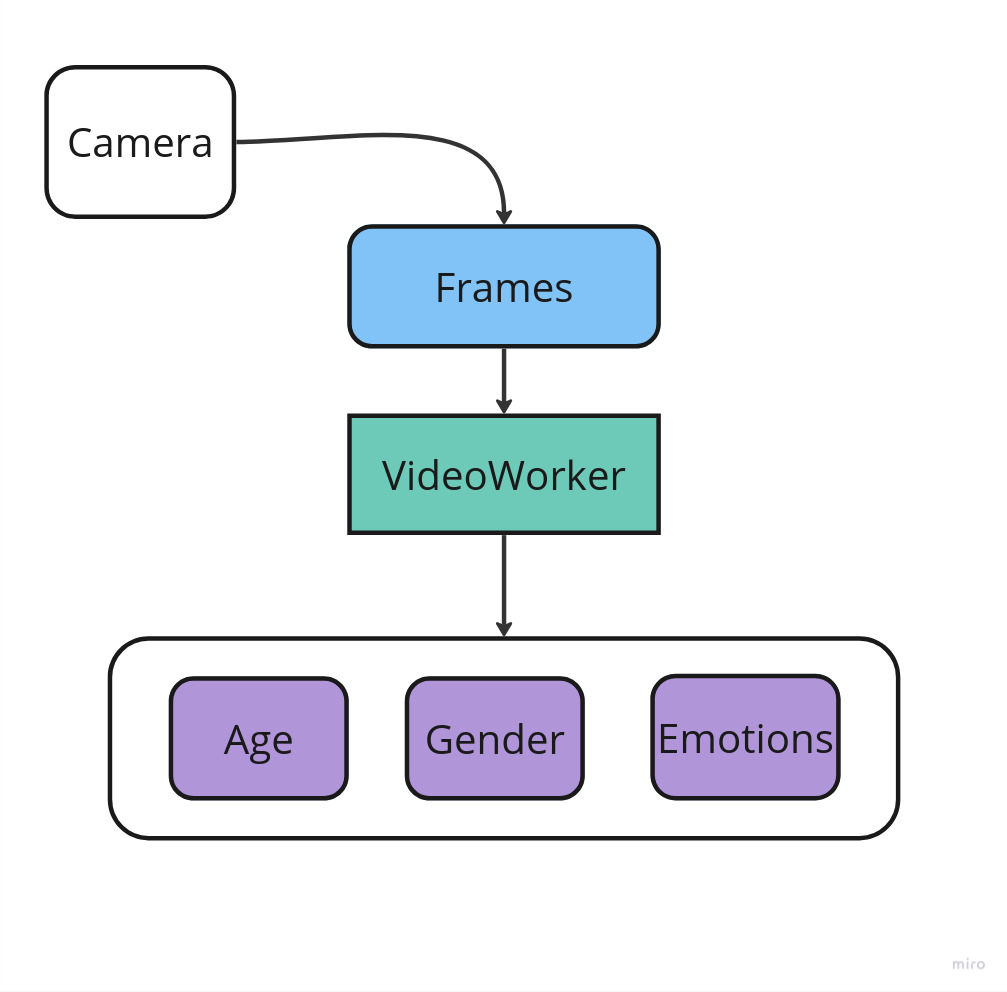
The standard option to estimate age, gender, and emotions in video stream is to use the VideoWorker object. The Frames received from the Camera are passed to VideoWorker object. As a result, the information about age, gender, and emotions is returned to VideoWorker::TrackingCallbackU.
Face estimation in images
- Legacy API
- Processing Block API
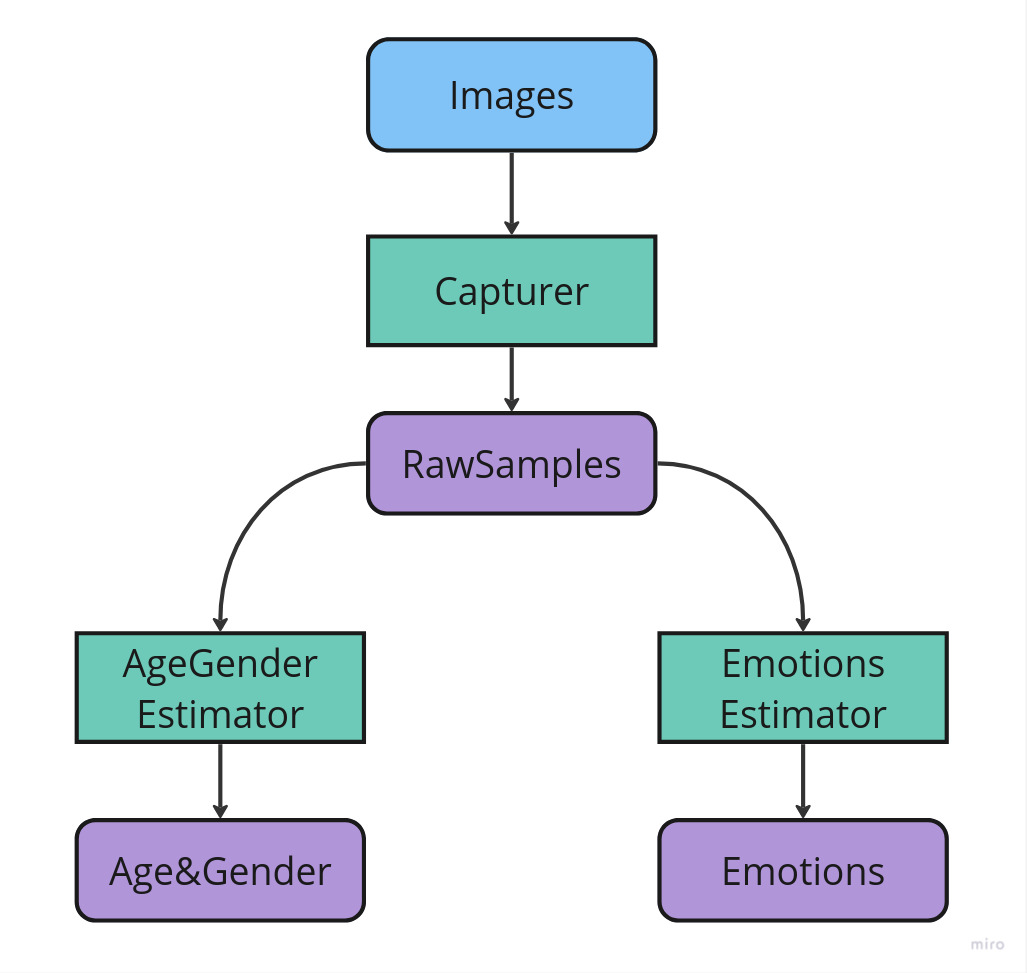
You can use this option if face estimation with VideoWorker is not suitable for your case (for example, if you need to estimate faces in images). The Frames received from the Camera are passed to the Capturer object, used to detect faces. Detected faces and information about them (RawSample) are passed for further processing to the AgeGenderEstimator and EmotionsEstimator objects, which return age and gender and emotions respectively.
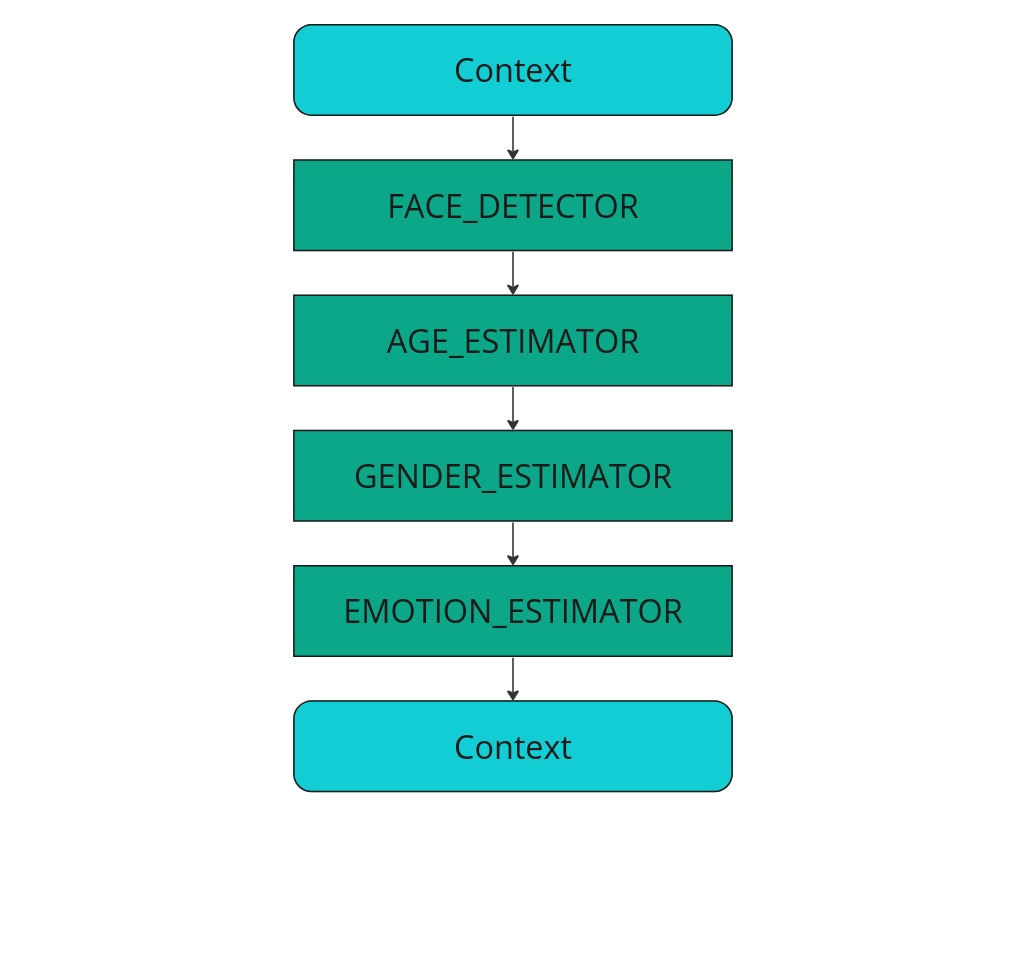
If the VideoWorker object-based face estimation is not suitable for you (for example, if face estimation from images is required), you can opt for this scenario. An image Context-container is created and passed to the face detection processing block (FACE_DETECTOR). The detection outcome is saved in the original Context-container and transmitted to subsequent processing blocks for age estimation (AGE_ESTIMATOR), gender estimation (GENDER_ESTIMATOR), and emotion analysis (EMOTION_ESTIMATOR).
Database creation
- Legacy API
- Processing Block API
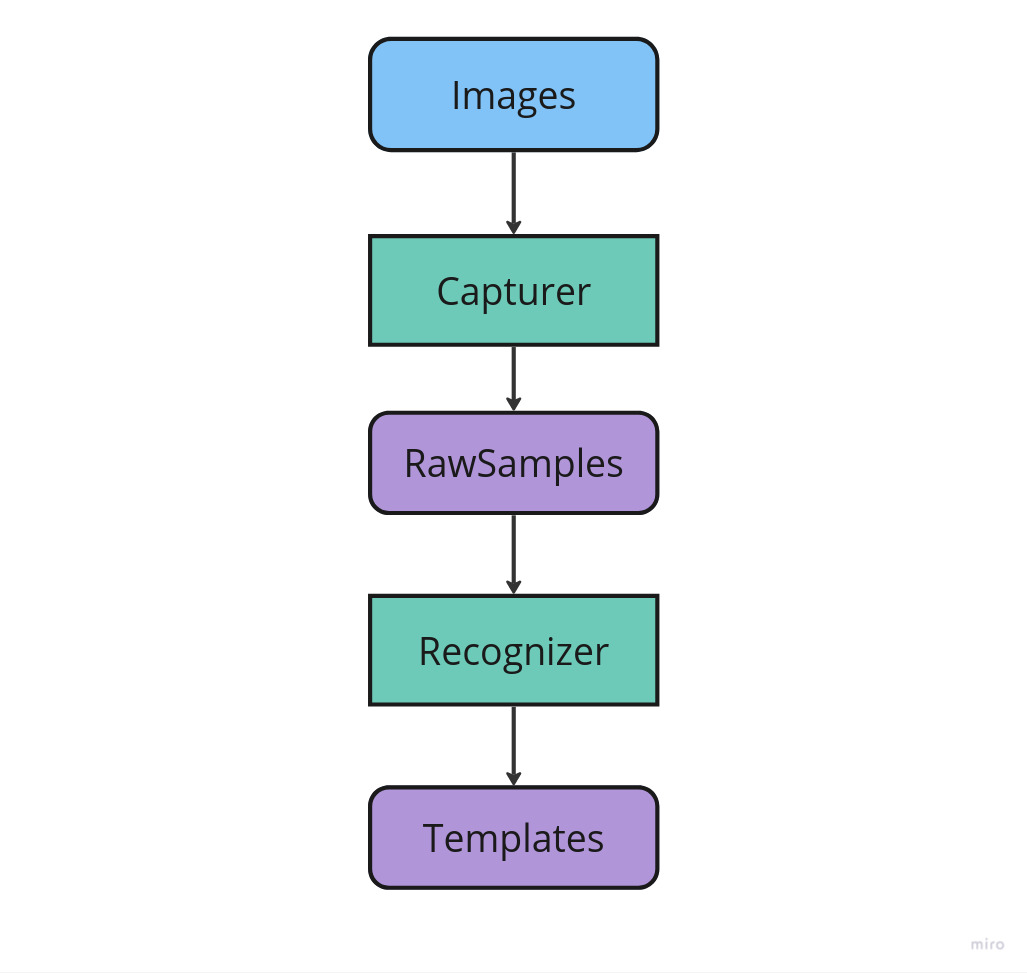
For face identification you need to create a template database (only once). Images are passed to the Capturer object. Detected faces and information about them (RawSample) are passed to the Recognizer object, which returns biometric templates (Template). The operation of receiving the templates is time-consuming. Therefore, there is a special tool, which lets you save a template to long-term memory (see the methods Template::save, Recognizer::loadTemplate).
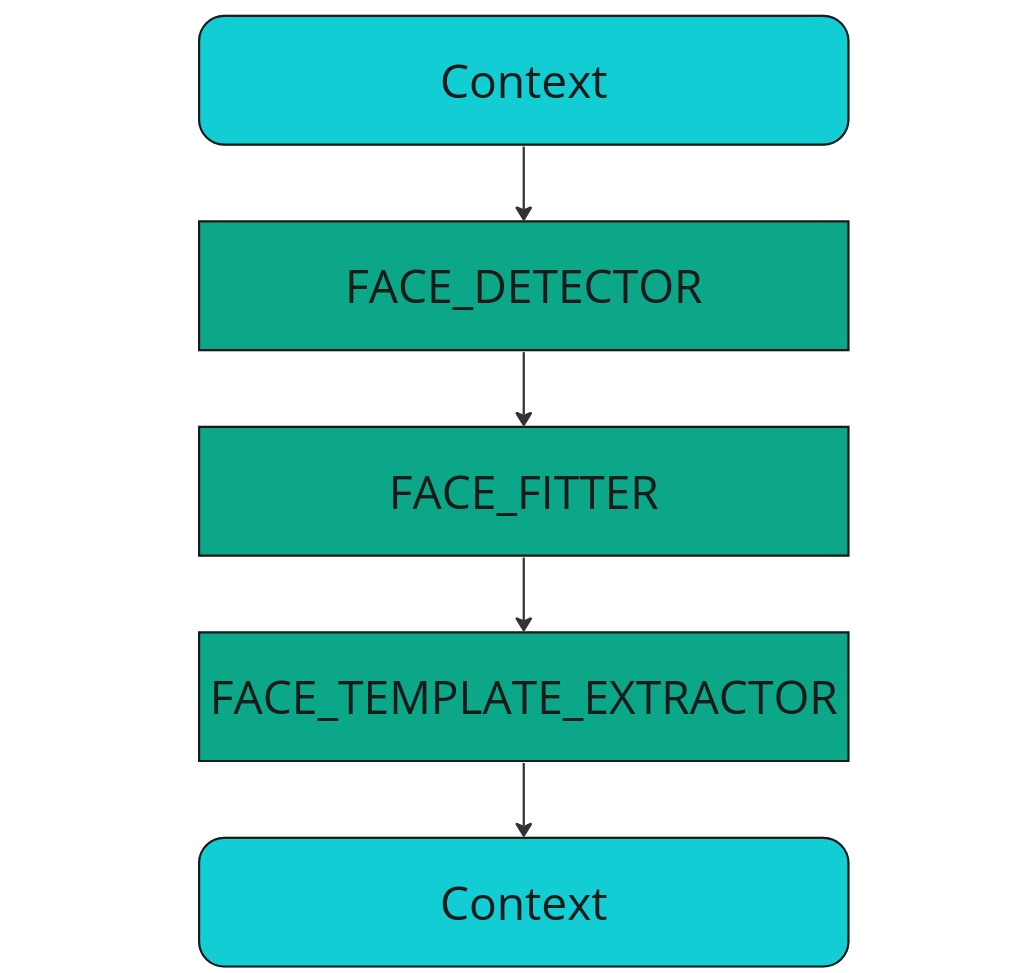
For face identification you only need to create a biometric template database once. An image Context-container is generated and passed to the face detection processing block (FACE_DETECTOR). The detection results are saved in the original Context-container and forwarded to the face fitter processing block (FACE_FITTER) to obtain anthropometric face points. The results are then sent to the face template extractor processing block (FACE_TEMPLATE_EXTRACTOR), which returns a Context containing the biometric templates. Processing templates for large databases can be time-consuming, so the generated templates can be stored in long-term memory for future use.
Face identification in video stream
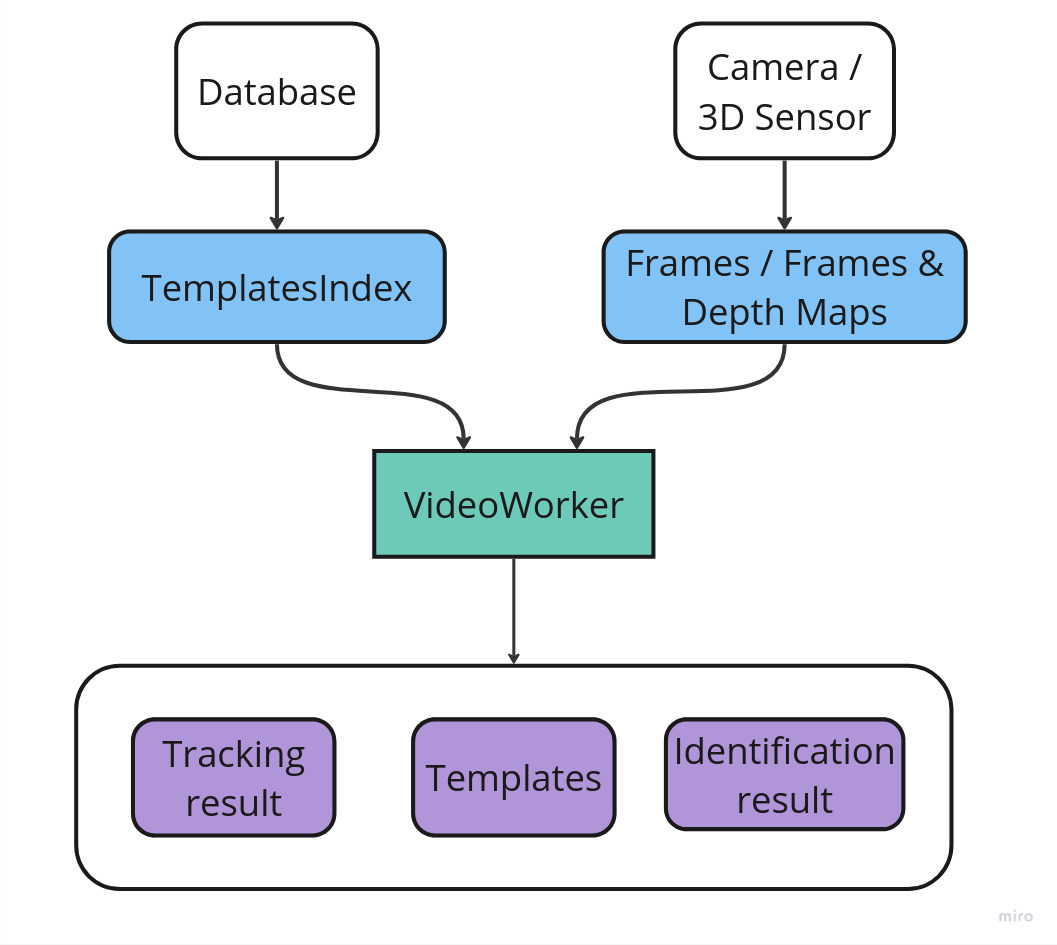
The standard option to identify faces in video stream is to use the VideoWorker object. The Frames received from the Camera are passed to VideoWorker. If you use a 3D sensor, a Depth Map is also passed to VideoWorker. The information about detected and recognized faces and created templates is returned in callbacks.
Face identification (RGB camera)
- Legacy API
- Processing Block API
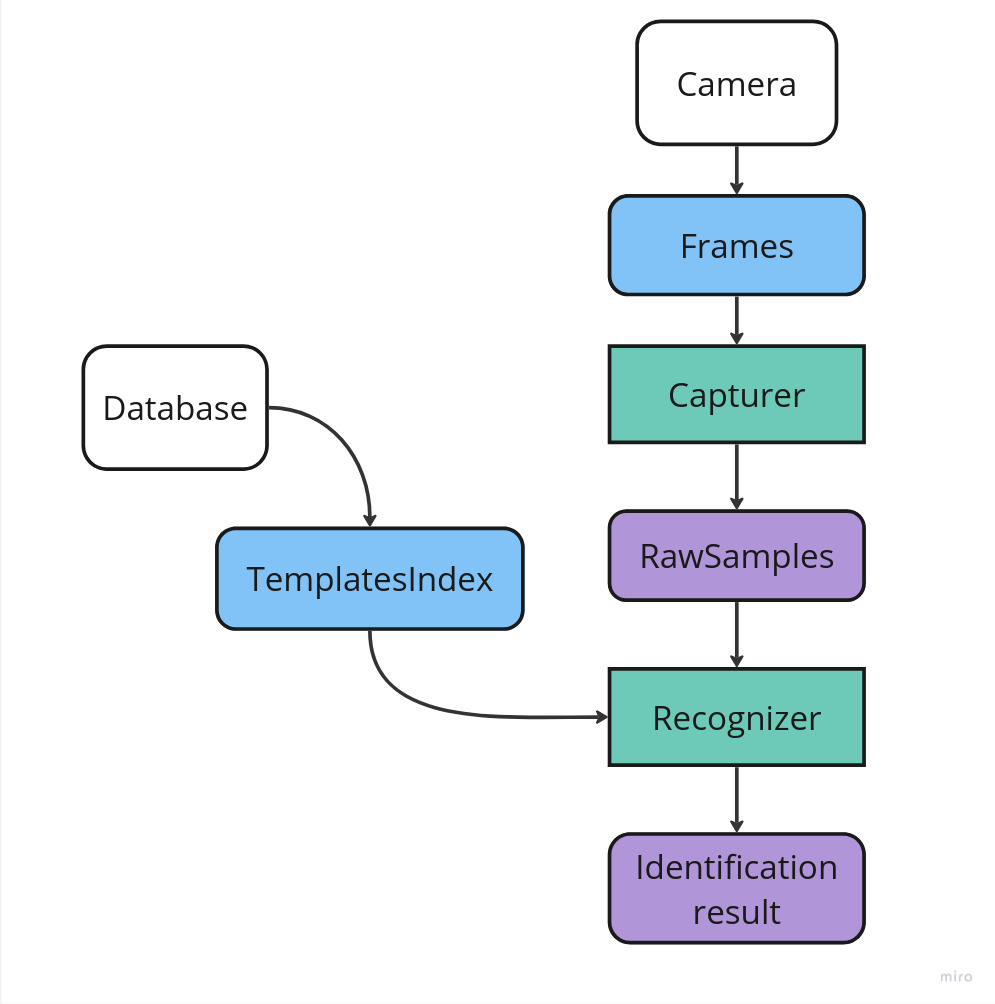
The Frames received from the Camera are passed to the Capturer object, used to detect faces. Detected faces and information about them (RawSample) and template database (TemplatesIndex, see Database Creation) are passed to the Recognizer object. Recognizer extracts biometric templates from RawSample and compares them with templates from the database.
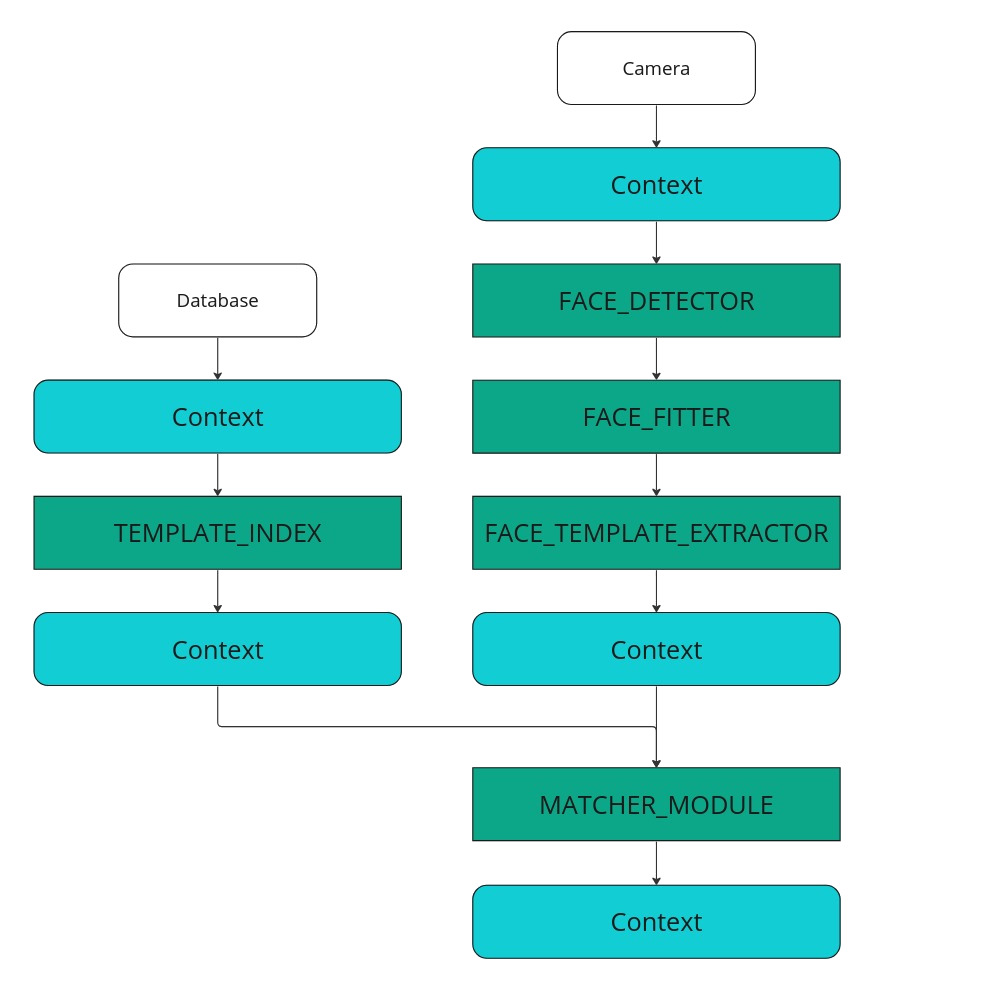
Frames from the camera are processed through face detection (FACE_DETECTOR), face fitting (FACE_FITTER), and template extraction (FACE_TEMPLATE_EXTRACTOR) blocks to obtain a face template in a container context. The resulting template, along with the existing face database (TEMPLATE_INDEX, see section Database Creation), is then sent to the matching processing block MATCHER_MODULE, which compares the template with templates from the face database.
Face identification (with Liveness check)
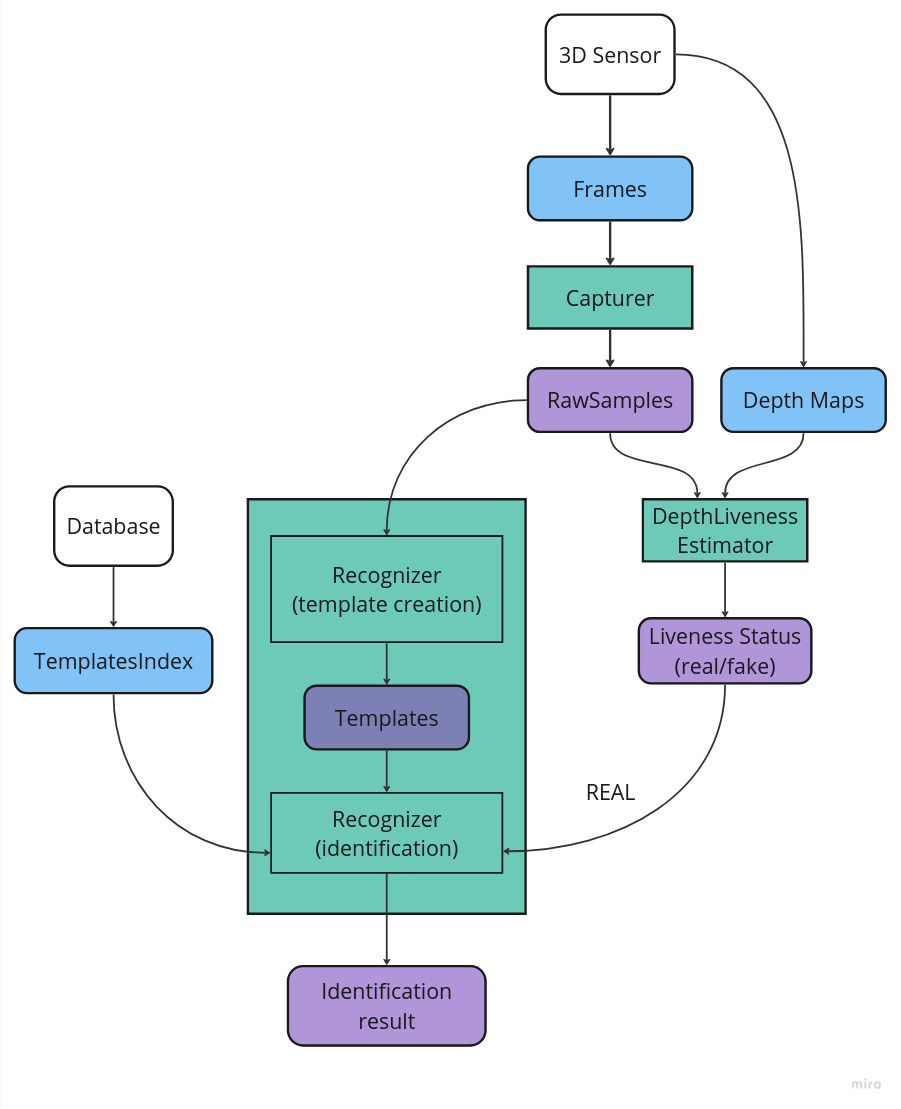
This diagram is similar to the previous one, the only difference is a depth map received from a 3D Sensor. The depth map is passed to the DepthLivenessEstimator object for Liveness estimation. If the returned status is REAL, the detected faces and information about them (RawSample) are passed for further processing to Recognizer.