6. Troubleshooting
Error occurred when generating offline license request
Problem: when executing a command ./setup/activate-lic-server.sh --generate-offline you can get the following error:
ERR Missing file path for offline activation request file! Specify path using ‘--offline-request’ option.
Solution: ensure that the file ./setup/settings.env contains a license key in LIC_KEY variable and a license server address in LIC_SERVER_URL variable.
Error occurred when installing Docker, Kubernetes and Helm
Problem: when executing a script command on_premise/setup/install-packages.sh you can receive the following error:
E: Sub-process /usr/bin/dpkg returned an error code (1)
Solution 1: the error can be caused by a corrupted dpkg database. In this case, reconfigure the dpkg package manager with the command:
$ sudo dpkg --configure -a
Solution 2: if errors appear during the installation of software packages, you can force the installation of the package using -f option:
$ sudo apt install -f
OR
$ sudo apt install --fix-broken
Options -f and --fix-broken can be interchangeably used to fix broken dependencies resulting from an interrupted package download.
Solution 3: if the first two solutions did not fix the problem, you can remove or purge the problematic software package as shown below:
$ sudo apt remove --purge package_name
Solution 4: you can also manually remove all files associated with the problematic package by running the command below. The files are located in the directory /var/lib/dpkg/info.
$ sudo ls -l /var/lib/dpkg/info | grep -i package_name
After listing the files, you can move them to the /tmp directory as shown below:
$ sudo mv /var/lib/dpkg/info/package-name.* /tmp
Alternatively, you can use the rm command to manually remove the files.
$ sudo rm -r /var/lib/dpkg/info/package-name.*
Error with nvidia-device-plugin when checking cluster components
Problem: when executing a command kubectl get all --all-namespaces you can receive the following error:
Error: failed to start container "nvidia-device-plugin-ctr": Error response from daemon: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: error during container init: error running hook #0: error running hook: exit status 1, stdout: , stderr: Auto-detected mode as 'legacy'
nvidia-container-cli: initialization error: nvml error: driver/library version mismatch: unknown
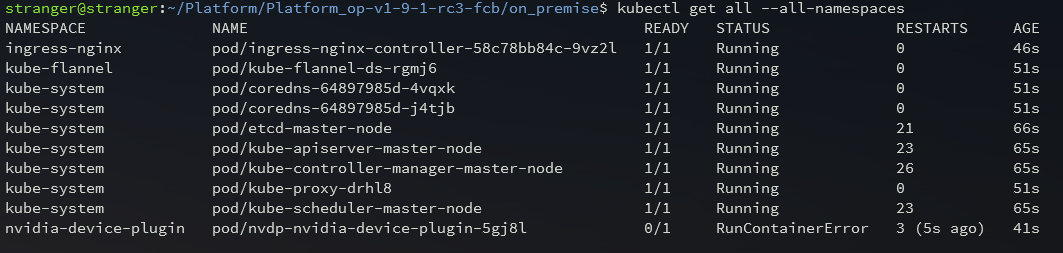
Solution:
- For information about your graphics card and available drivers, run the following command:
ubuntu-drivers devices
- The console output indicates that the system has a "GeForce GTX 1050 Ti" graphics card and the recommended driver "nvidia-driver-515".
== /sys/devices/pci0000:00/0000:00:10.0 ==
modalias : pci:v000010DEd00001C82sv00001458sd00003764bc03sc00i00
vendor : NVIDIA Corporation
model : GP107 [GeForce GTX 1050 Ti]
manual_install: True
driver : nvidia-driver-510-server - distro non-free
driver : nvidia-driver-450-server - distro non-free
driver : nvidia-driver-390 - distro non-free
driver : nvidia-driver-520 - distro non-free
driver : nvidia-driver-418-server - distro non-free
driver : nvidia-driver-515-server - distro non-free
driver : nvidia-driver-515 - distro non-free recommended
driver : nvidia-driver-510 - distro non-free
driver : nvidia-driver-470-server - distro non-free
driver : nvidia-driver-470 - distro non-free
driver : xserver-xorg-video-nouveau - distro free builtin
- To install the recommended driver, run the command:
sudo apt install nvidia-driver-515
- After installing the driver, you can view the status of the graphics card using the
nvidia-smimonitoring tool:
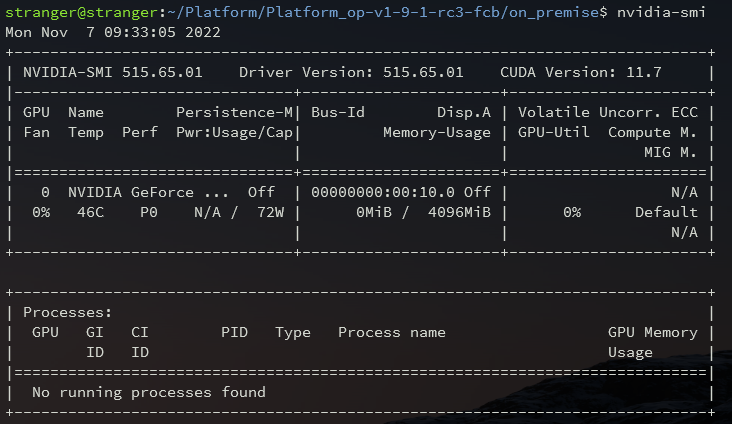
- You can view the driver version using the command:
cat /proc/driver/nvidia/version

Error occurred when deploying the Platform in a cluster
Problem: not all services are started up when executing a command ./setup/deploy.sh.
Solution: Request the log db-dep using the command:
kubectl logs -f <full name of pod>
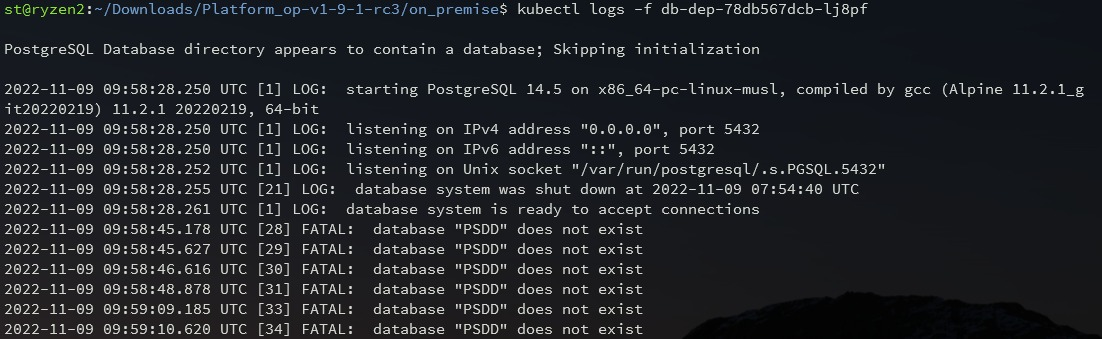
If the output shows an error on incorrect database name or authorization data, redeploy the cluster (See the section 2.1).
Error occurred when uploading images to external registry
Problem: when uploading images you can get the following error:
The push refers to repository [<DOCKER_REGISTRY_SERVER>/<IMAGE>]
Get "<DOCKER_REGISTRY_SERVER>/v2/": x509: certificate signed by unknown authority
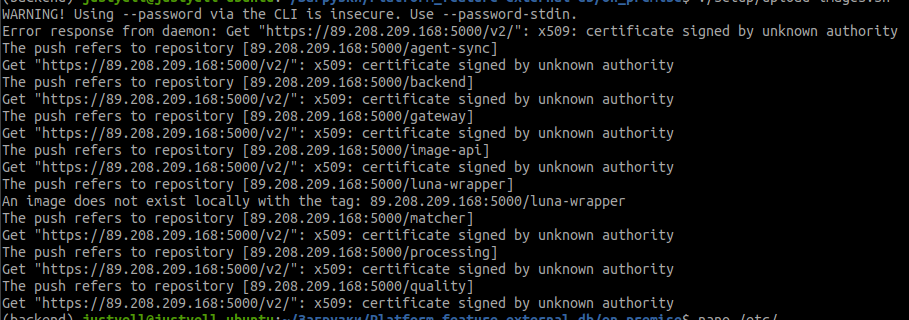
Solution: Add or change the file /etc/docker/daemon.json and add your DOCKER_REGISTRY_SERVER to the list of insecure-registries:
{
"insecure-registries" : [ "<DOCKER_REGISTRY_SERVER>" ]
}
Restart docker-service using the command below:
$ sudo systemctl restart docker
All the rest memory of the system where OMNI Platform is installed is cached
Problem: During installation, operation, and scaling of OMNI Platform, it may happen that all the remaining memory of the work system is cached.
Solution: In this case, OS manages the buffer/cache, not the platform. Cached memory is not used by other applications, but if necessary, OS will allocate it by reducing the buffer size.
Insufficient percentage of detected faces
Problem: The percentage of faces detected by the platform may not be sufficient for a specific use case.
Solution: In this case, you need to configure the parameters of the detector used (increase the detection threshold and the minimum and maximum sizes of the detected face).
To do this, stop the platform, open the on_premise/deploy/values.yaml file, and add the following line to the env block:
FACE_SDK_PARAMETERS: "{\\"score_threshold\\": 0.7, \\"min_size\\": 150, \\"``max_size\\": 10000}" , where:
score_threshold - detection threshold, from 0 to 1. The higher the threshold value, the more faces the detector can recognize;
min_size , max_size - minimum and maximum face size for detection, in pixels.